About p300-speller , I was looking at the p300-speller-2-trian-clasiffier.xml, this is the training scenario and the p300-speller-1-acquisition.xml where we use in real-time to recognize the characters. Am I correct?
I used the bci-p300-speller.ov file as given in the example for the training purposes. Finally once the training is over, the word “MRVZV9NUGE” appears in front of the Target label (of the p300 speller visualization window)and nothing in the Result label, why is this? And what does Target and Result label represent (in the p300 speller visualization window) ?
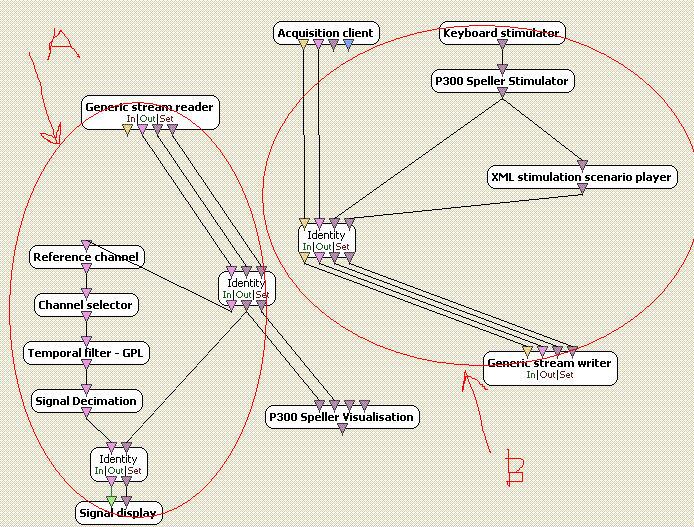
Now in the p300-speller-1-acquisition.xml , What does A and B do in the image shown ?
I am trying to experiment the p300 speller by using offline data (without connecting to a EEG machine), therefore how do I modify this scenario to play it in an offline mode?
help appreciated
 my blog
my blog my tweets
my tweets my linkedin
my linkedin